データ重複除去機能は、
・データの正確性、整合性を損なうことなく重複を見つけて除去する
・ファイルを可変サイズのチャンク(32-128KB)に分割し、重複するチャンクを除去し、1つだけ残されたチャンクの参照になる
・システムドライブは設定不可能
・原理上、ファイルAというものが2GBでそれを単純に同一ドライブ内でコピーしたら、通常であれば4GB、重複除去設定をすれば2GBということ(だと思う)
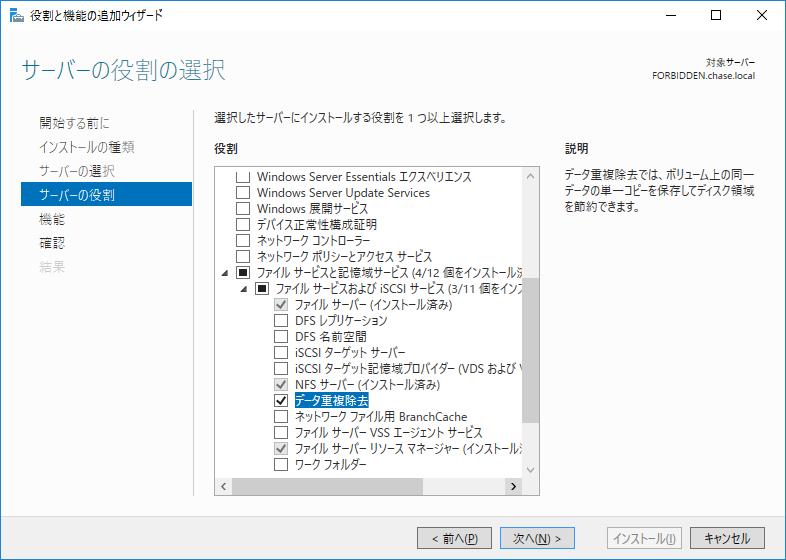
サーバーマネージャーからインストールするだけ。
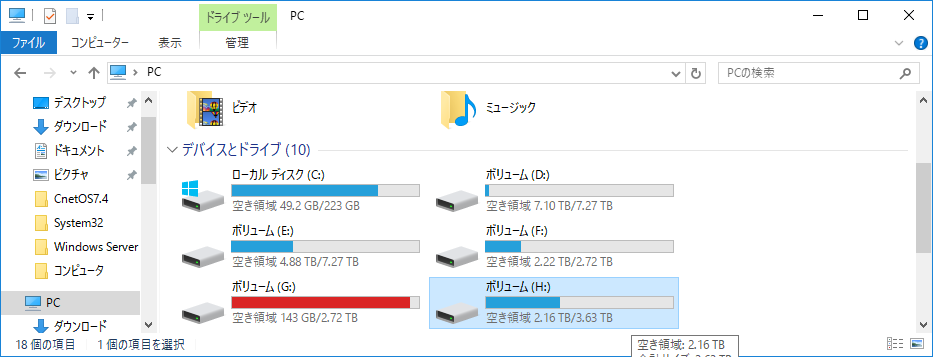
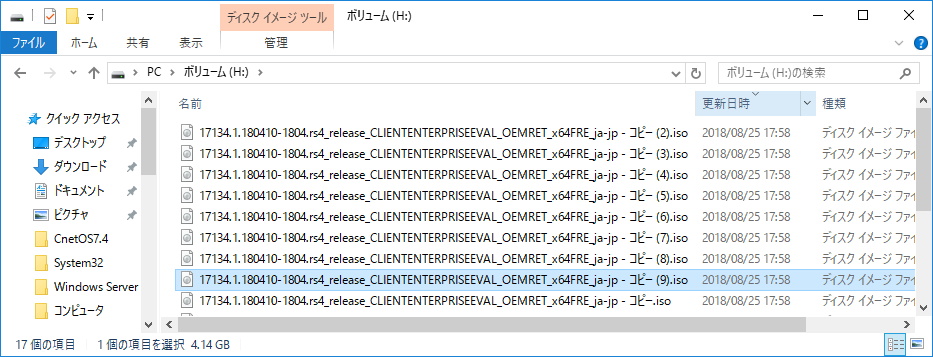
試す対象はHドライブ。とりあえず適当な4GB程度のISOファイルを10個くらいコピってみた。
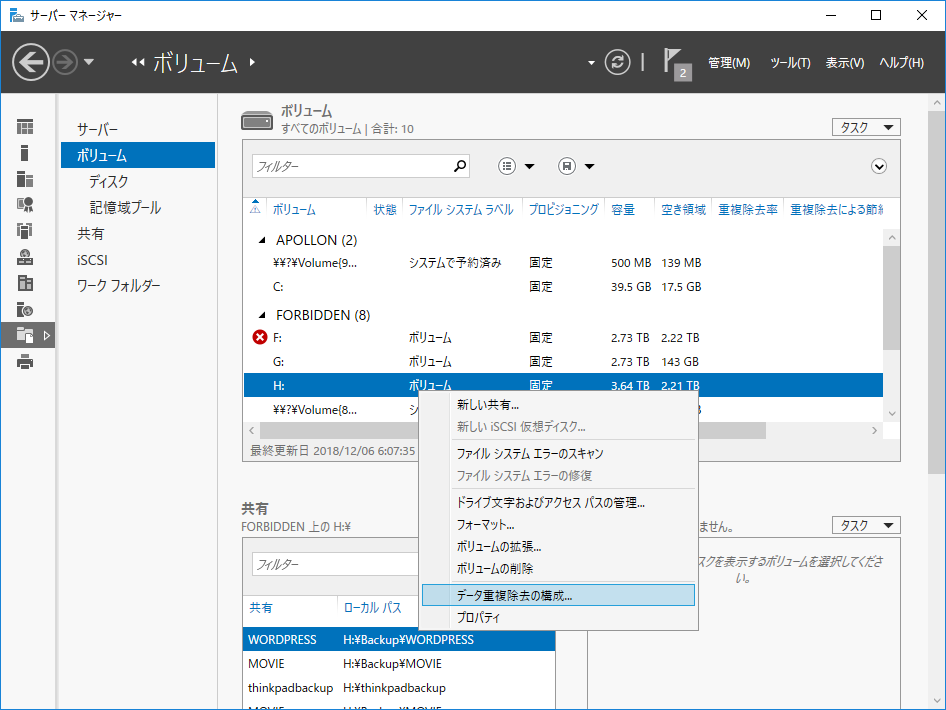
サーバーマネージャーの「ファイルサービスと記憶域サービス」-「ボリューム」-「データ重複除去の構成」を選択
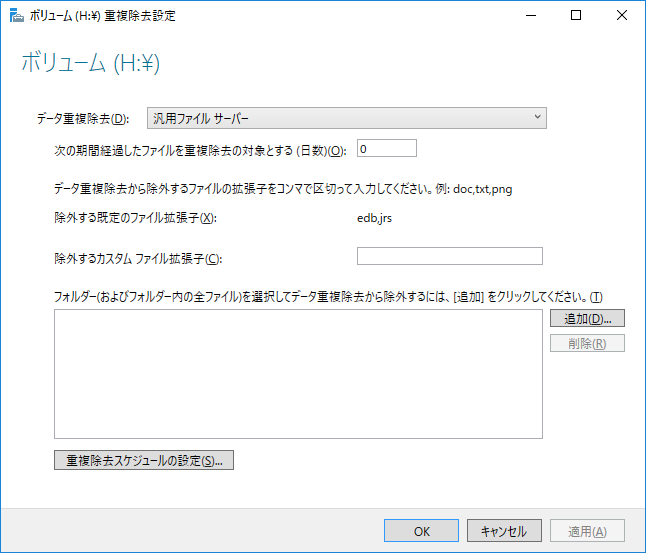
「汎用ファイルサーバー」を選択し、日数を「0」にして、「OK」。
※日数「0」だと、即時実行
もちろん、Powershellでの実行をできる
# 手動開始 PS C:\Users\administrator.CHASE> Start-DedupJob -Type Optimization -Volume H: -Memory 100 -Cores 100 -Priority High Type ScheduleType StartTime Progress State Volume ---- ------------ --------- -------- ----- ------ Optimization Manual 0 % Queued H: PS C:\Users\administrator.CHASE> # 実行確認 PS C:\Users\administrator.CHASE> Get-DedupJob Type ScheduleType StartTime Progress State Volume ---- ------------ --------- -------- ----- ------ Optimization Manual 6:36 0 % Running H: PS C:\Users\administrator.CHASE> # 手動停止 PS C:\Users\administrator.CHASE> Stop-DedupJob -Type Optimization -Volume H: PS C:\Users\administrator.CHASE> Get-DedupJob Type ScheduleType StartTime Progress State Volume ---- ------------ --------- -------- ----- ------ Optimization Manual 6:38 1 % Running H: PS C:\Users\administrator.CHASE> Get-DedupJob PS C:\Users\administrator.CHASE>
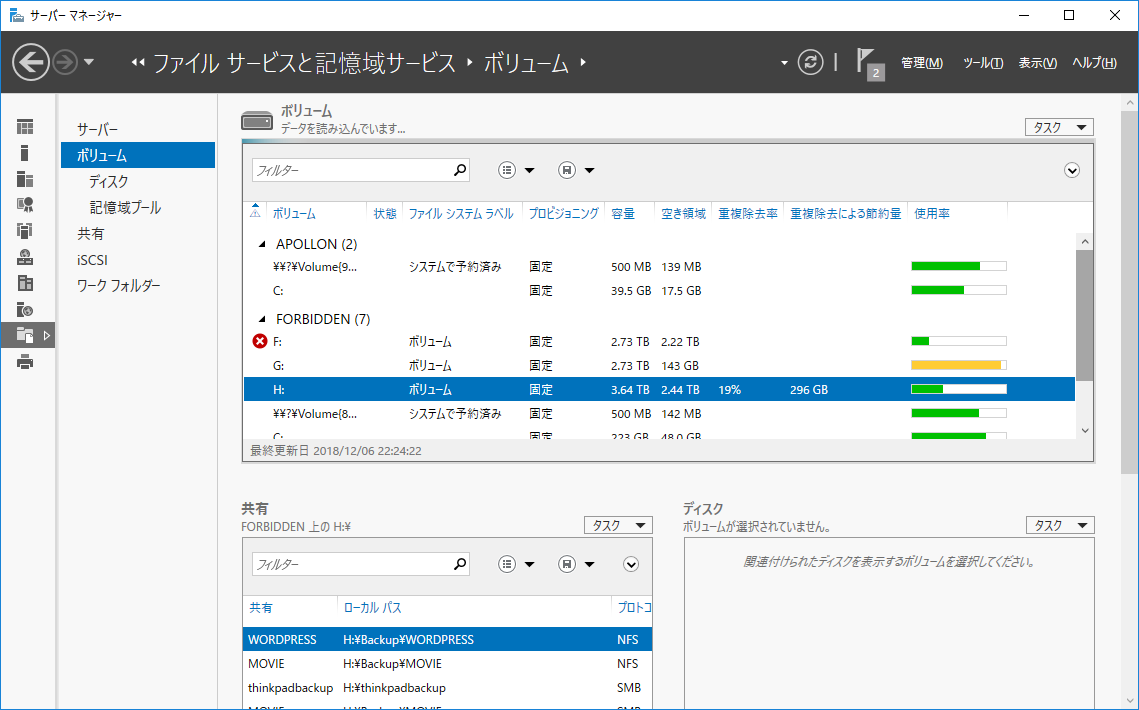
結果発表。3TBで12時間以上はかかっていたと思う。
19%も重複があったみたいで、2100GB中の300GB近く容量の空きができた。